### Введение
Планирование (scheduling) в Kubernetes — это механизм, который определяет **где именно будет запущен Pod**. В production-кластерах почти никогда не требуется жёсткая привязка к конкретной ноде. Вместо этого Kubernetes предлагает **декларативные и гибкие инструменты управления размещением нагрузки**:
- **Node Affinity** — логика _выбора_ подходящих нод
- **Taints & Tolerations** — логика _ограничения доступа_ к нодам
Эти механизмы работают совместно с kube-scheduler и позволяют строить масштабируемые, отказоустойчивые и управляемые кластеры.
---
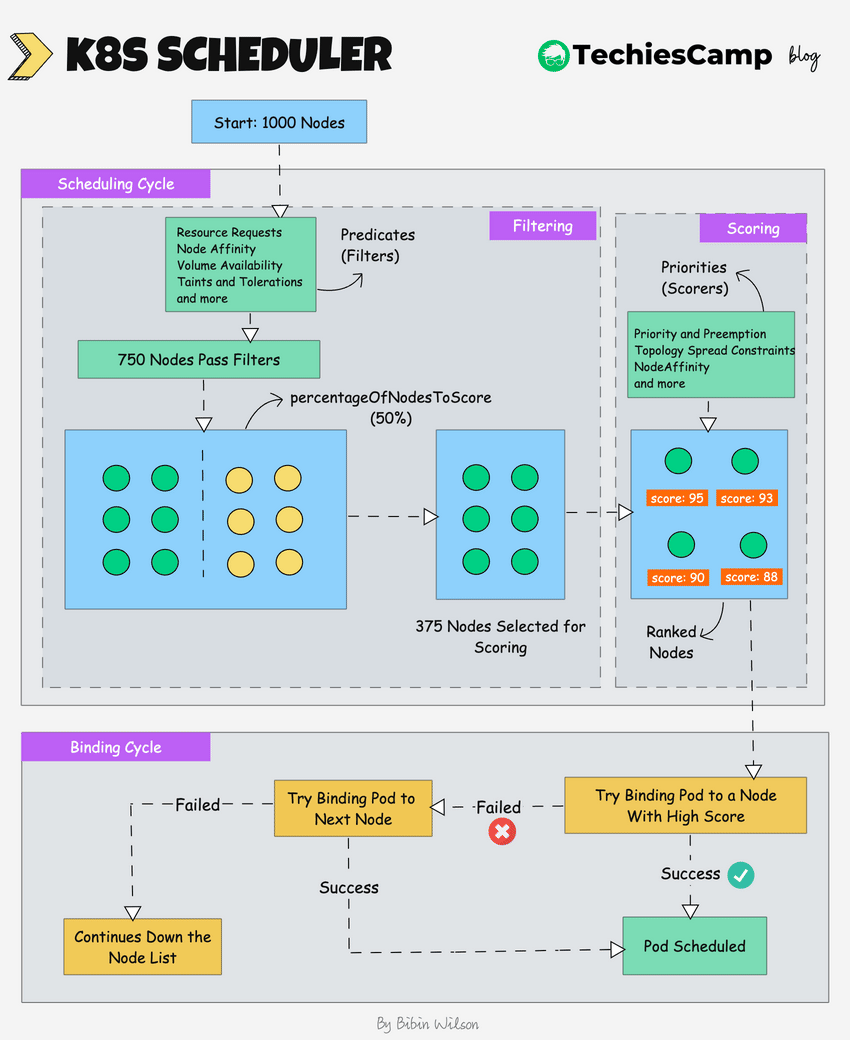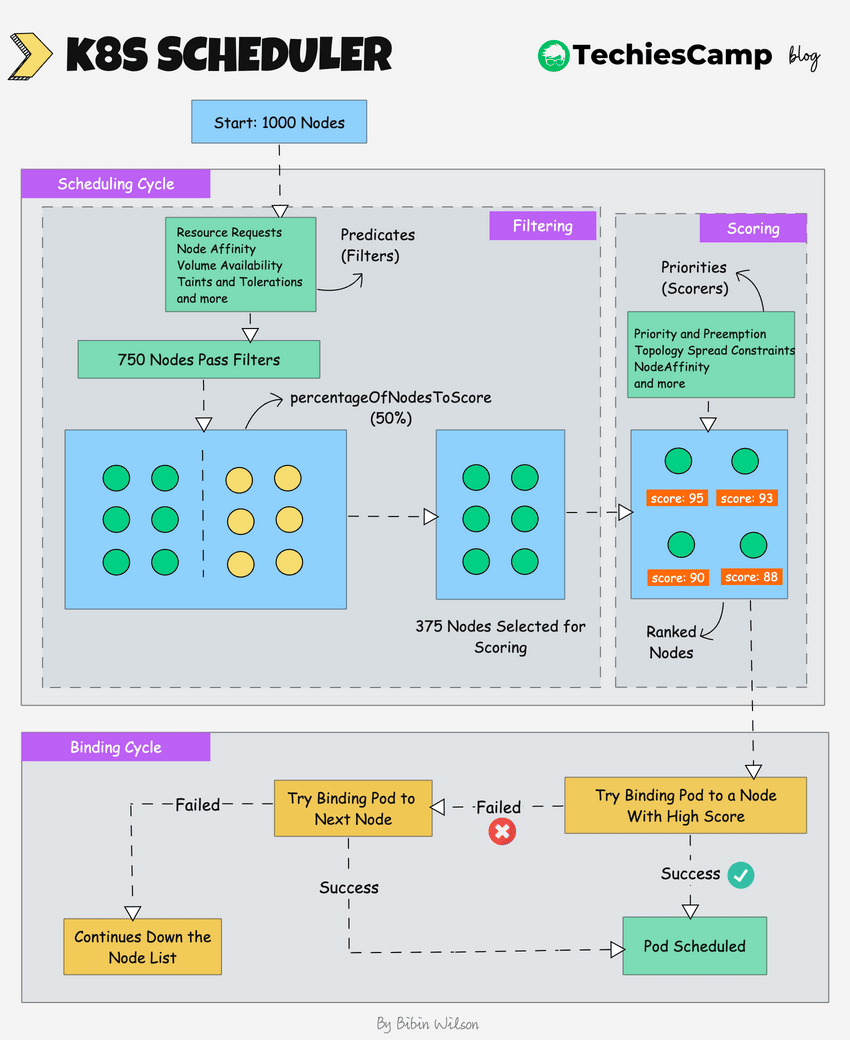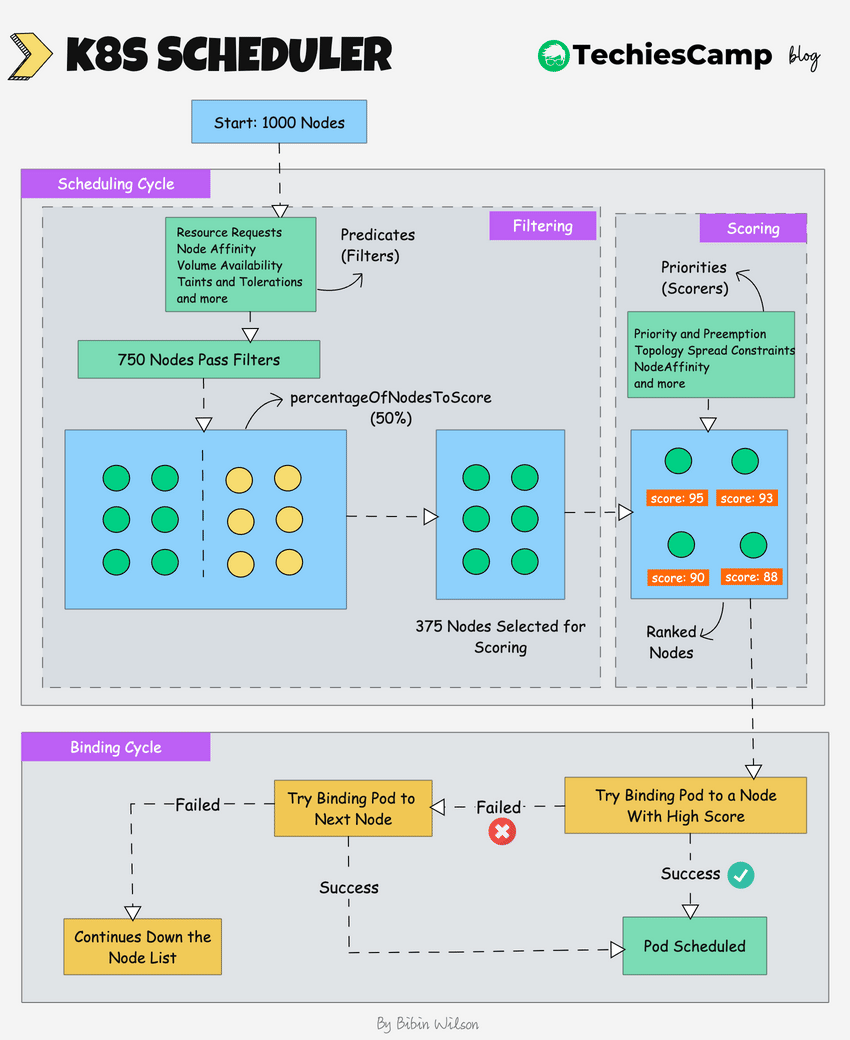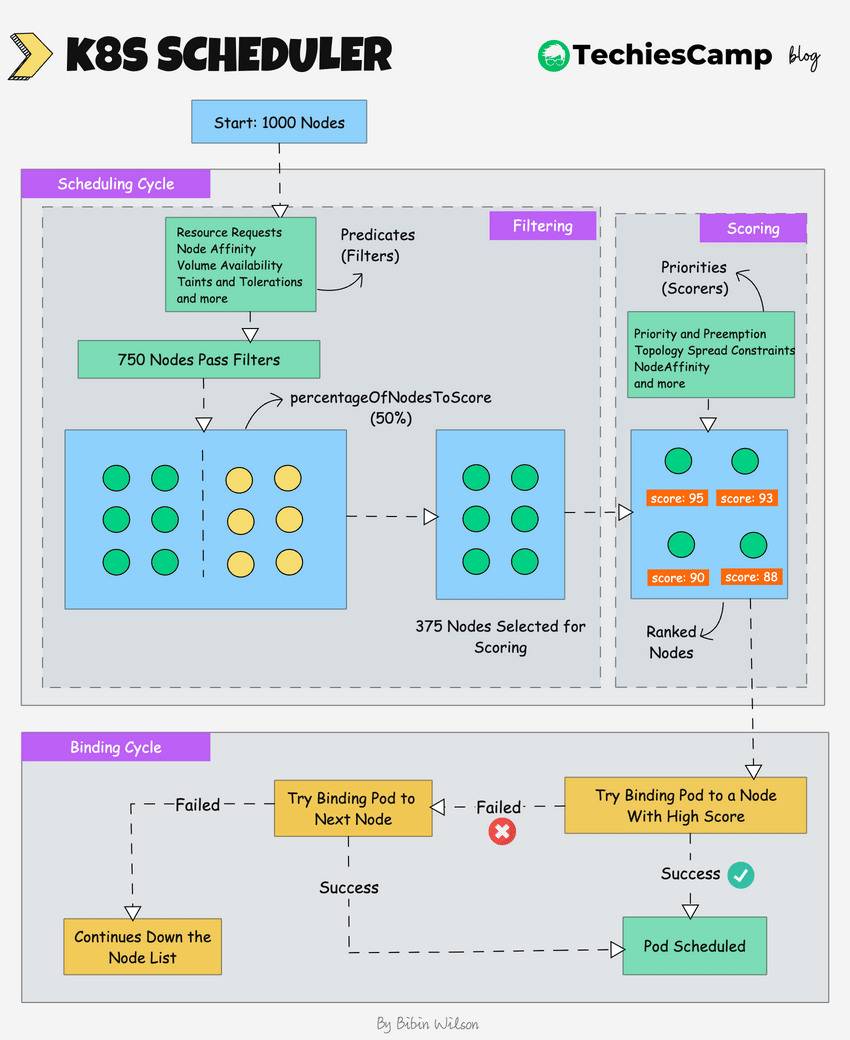
## Как kube-scheduler принимает решение
В упрощённом виде scheduler проходит три логических этапа:
1. **Filter** — отбрасывает ноды, которые не подходят (ресурсы, taints, affinity)
2. **Score** — оценивает оставшиеся ноды по различным критериям
3. **Bind** — привязывает Pod к выбранной ноде
Affinity и taints/tolerations участвуют именно на этапах **Filter** и **Score**, не ломая работу scheduler’а, а направляя его.
---
## Node Affinity: управление выбором нод
Node Affinity — это развитие `nodeSelector`. Она позволяет описывать **условия размещения Pod’ов на нодах**, используя логические выражения и режимы строгости.
### Подготовка нод
Добавим метки нодам:
```bash
kubectl label nodes worker-1 zone=eu-central
kubectl label nodes worker-2 zone=eu-west
kubectl label nodes worker-3 zone=eu-central
```
Проверка:
```bash
kubectl get nodes --show-labels
```
---
### requiredDuringSchedulingIgnoredDuringExecution
**Жёсткое требование**: Pod **не будет запущен**, если нет подходящих нод.
```yaml
apiVersion: v1
kind: Pod
metadata:
name: app-required-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- eu-central
containers:
- name: app
image: nginx
```
Результат:
- Pod может быть запущен **только** на `worker-1` или `worker-3`
- если все такие ноды недоступны → `Pending`
Это основной механизм для:
- разделения по зонам
- hardware-aware scheduling (SSD, GPU)
- регуляторных требований
---
### preferredDuringSchedulingIgnoredDuringExecution
**Мягкое предпочтение**: scheduler _старается_, но не гарантирует.
```yaml
apiVersion: v1
kind: Pod
metadata:
name: app-preferred-affinity
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: zone
operator: In
values:
- eu-central
containers:
- name: app
image: nginx
```
Поведение:
- если есть `eu-central` → Pod пойдёт туда
- если нет → будет выбран любой доступный узел
Используется для:
- оптимизации latency
- балансировки по зонам
- “best effort” размещения
---
### Несколько условий affinity
```yaml
matchExpressions:
- key: zone
operator: In
values: ["eu-central"]
- key: disktype
operator: In
values: ["ssd"]
```
Интерпретация:
- логика **AND** внутри одного `matchExpressions`
- логика **OR** между `nodeSelectorTerms`
---
## Taints и Tolerations: контроль доступа к нодам
Если affinity отвечает на вопрос
> _«Куда можно?»_
то taints отвечают
> _«Кому нельзя?»_
---
## Что такое `nodeName`
`nodeName` — это **прямое указание Kubernetes**:
> «Запусти этот Pod **только** на конкретной ноде с таким именем».
Когда `nodeName` задан:
- kube-scheduler **полностью пропускается**
- Kubernetes **не делает проверок** на ресурсы, affinity и балансировку
- kubelet на указанной ноде либо запускает Pod, либо Pod зависает в `Pending`
---
## Пример Pod с `nodeName`
`apiVersion: v1 kind: Pod metadata: name: nginx-fixed-node spec: nodeName: worker-1 containers: - name: nginx image: nginx`
Применяем:
`kubectl apply -f pod.yaml`
Проверяем:
`kubectl get pod nginx-fixed-node -o wide`
Вывод:
`NAME READY STATUS NODE nginx-fixed-node 1/1 Running worker-1`
Pod **никогда** не будет запущен ни на какой другой ноде.
### Taint: пометить ноду как “закрытую”
```bash
kubectl taint nodes worker-1 dedicated=infra:NoSchedule
```
Проверка:
```bash
kubectl describe node worker-1 | grep Taint
```
Теперь:
- **ни один Pod не будет запланирован** на эту ноду
- кроме Pod’ов с соответствующей toleration
---
### Pod без toleration
```yaml
apiVersion: v1
kind: Pod
metadata:
name: app-no-toleration
spec:
containers:
- name: app
image: nginx
```
Результат:
- Pod **никогда не попадёт** на `worker-1`
- scheduler исключит ноду на этапе Filter
---
### Pod с toleration
```yaml
apiVersion: v1
kind: Pod
metadata:
name: app-with-toleration
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "infra"
effect: "NoSchedule"
containers:
- name: app
image: nginx
```
Теперь Pod:
- **имеет право** запускаться на `worker-1`
- но **не обязан** — scheduler всё ещё выбирает оптимальную ноду
---
### Основные эффекты taints
|Effect|Поведение|
|---|---|
|`NoSchedule`|новые Pod’ы не планируются|
|`PreferNoSchedule`|старается не планировать|
|`NoExecute`|удаляет уже запущенные Pod’ы|
---
### NoExecute и eviction
```bash
kubectl taint node worker-2 maintenance=true:NoExecute
```
Pod без toleration:
- будет **удалён** с ноды
Pod с toleration:
```yaml
tolerations:
- key: "maintenance"
operator: "Equal"
value: "true"
effect: "NoExecute"
tolerationSeconds: 300
```
Поведение:
- Pod живёт 5 минут
- затем удаляется
Используется для:
- graceful maintenance
- drain нод без downtime
---
## Совместное использование Affinity и Taints
Типичный production-паттерн:
```yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role
operator: In
values: ["infra"]
tolerations:
- key: "dedicated"
operator: "Equal"
value: "infra"
effect: "NoSchedule"
```
Логика:
- affinity **выбирает** infra-ноды
- taint **защищает** их от случайных Pod’ов
- toleration **разрешает доступ** нужным workload’ам
---
# Kubernetes Scheduling на практике
### `kubectl describe pod`: реальные events + паттерны для k3s и bare-metal

---
## Почему `kubectl describe pod` — главный инструмент для понимания scheduler’а
Если Pod находится в `Pending`, **90% всей правды уже есть в Events**.
`scheduler`, `kubelet`, `controller-manager` — все они пишут туда свои решения и ошибки.
Команда:
```bash
kubectl describe pod <pod-name>
```
Ключевой раздел:
```text
Events:
Type Reason Age From Message
```
Именно здесь видно:
- **почему Pod не запланирован**
- **какие ноды были отфильтрованы**
- **какое правило affinity / taint сработало**
---
## Кейc 1: Node Affinity — нет подходящих нод
### Pod с required node affinity
```yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- eu-central
```
### Вывод `kubectl describe pod`
```text
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 12s default-scheduler 0/3 nodes are available:
3 node(s) didn't match Pod's node affinity/selector.
```
### Что здесь происходит
- scheduler просмотрел **все 3 ноды**
- ни у одной **нет label `zone=eu-central`**
- фильтрация произошла на этапе **Filter**
- Pod остался в `Pending`
📌 Важно:
scheduler **не пытается “почти” угадать** — `required` = жёсткое правило.
---
## Кейc 2: preferred affinity — Pod запланирован, но не туда
### Affinity с предпочтением
```yaml
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: zone
operator: In
values:
- eu-central
```
### Events
```text
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 8s default-scheduler Successfully assigned default/app to worker-2
```
### Интерпретация
- ноды с `eu-central` **были недоступны**
- правило `preferred` **не блокирует scheduling**
- Pod ушёл на `worker-2`, потому что:
- ресурсы были доступны
- штраф за отсутствие label меньше, чем отсутствие ресурсов
📌 Это типичное поведение для latency-оптимизаций.
---
## Кейc 3: Taint `NoSchedule` — нода исключена
### Нода с taint
```bash
kubectl taint node worker-1 dedicated=infra:NoSchedule
```
### Pod без toleration
### `kubectl describe pod`
```text
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 20s default-scheduler 0/3 nodes are available:
1 node(s) had taint {dedicated: infra}, that the pod didn't tolerate,
2 node(s) didn't have enough cpu.
```
### Что важно заметить
- scheduler **проверяет сразу все причины**
- сообщения агрегируются
- видно **точное количество нод по каждой причине**
📌 Это самый ценный вывод для production-debug.
---
## Кейc 4: `NoExecute` и eviction
### Нода переведена в maintenance
```bash
kubectl taint node worker-2 maintenance=true:NoExecute
```
### Pod без toleration
```text
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Killing 15s kubelet Stopping container app
Warning Evicted 14s kubelet Pod was evicted due to node taint
```
### Если есть toleration с `tolerationSeconds`
```yaml
tolerations:
- key: maintenance
operator: Equal
value: "true"
effect: NoExecute
tolerationSeconds: 300
```
Pod:
- остаётся **ровно 5 минут**
- затем kubelet инициирует eviction
---
## Как читать Events правильно (чек-лист)
При `FailedScheduling` смотри:
1. **0/N nodes are available**
2. Причины:
- affinity
- taints
- cpu / memory
- volume node affinity
3. Повторяется ли event каждые ~5 секунд
→ scheduler всё ещё пытается
---
# Паттерны scheduling для k3s и bare-metal
---
## Паттерн 1: Master/Control-plane isolation (k3s)
В k3s control-plane часто **совмещён с worker**, но его почти всегда изолируют.
### Taint control-plane
```bash
kubectl taint nodes k3s-master node-role.kubernetes.io/control-plane=true:NoSchedule
```
### Что это даёт
- пользовательские workload’ы туда не попадут
- system-компоненты (coredns, metrics-server) имеют tolerations
📌 Обязательный паттерн даже для single-node k3s.
---
## Паттерн 2: Infra-ноды (bare-metal)
### Ноды
```text
worker-1 role=infra
worker-2 role=infra
worker-3 role=app
worker-4 role=app
```
### Taint infra-нод
```bash
kubectl taint nodes -l role=infra dedicated=infra:NoSchedule
```
### Workload для infra
```yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values: ["infra"]
tolerations:
- key: dedicated
operator: Equal
value: infra
effect: NoSchedule
```
Используется для:
- ingress
- monitoring
- logging
- storage (Longhorn, Ceph)
---
## Паттерн 3: Storage-aware scheduling (bare-metal)
Частая ошибка: storage-Pod попал не туда.
### Label storage-нод
```bash
kubectl label nodes worker-1 storage=nvme
kubectl label nodes worker-2 storage=hdd
```
### Affinity для Longhorn / Ceph
```yaml
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: storage
operator: In
values: ["nvme"]
```
📌 Без этого volume может стать bottleneck’ом.
---
## Паттерн 4: Zone / rack awareness (bare-metal)
```bash
kubectl label nodes worker-1 rack=rack-a
kubectl label nodes worker-2 rack=rack-b
```
Используется вместе с:
- podAntiAffinity
- StatefulSet
Результат:
- реплики **физически разнесены**
- отказ одного rack ≠ outage сервиса
---
## Паттерн 5: k3s + single-node fallback
Для домашнего k3s:
- **не использовать required affinity**
- использовать `preferred`
- минимально применять taints
Причина:
- один узел = нет альтернатив
- жёсткие правила = вечный `Pending`
---